unpack
| Name | Type | Description | Optional |
|---|---|---|---|
input |
?0 |
a tuple |
no |
| Name | Type | Description | Optional |
|---|---|---|---|
taken from tuple type |
taken from tuple type |
first slot of the unpacked input tuple |
yes |
taken from tuple type |
taken from tuple type |
second slot of the unpacked input tuple |
yes |
… |
|||
taken from tuple type |
taken from tuple type |
final slot of the unpacked input tuple |
yes |
unpack takes an input of tuple type, and outputs the individual slots of all its tuple type and the tuple types nested within it.
Open the pattern called S3BucketCreateCopy. In the panel called ListObjects you will see this chain of nodes:
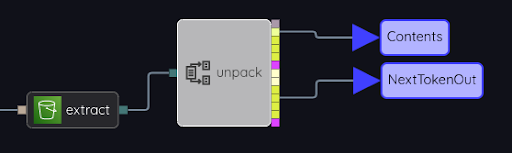
The extract node is a $AWS$S3$ListObjectsV2ResponseExtract node. Extract nodes are part of the Coreograph AWS SDK, and they are used to extract a structured response from the HTTP request that is returned by an AWS API. The type that is extracted is documented in the API call itself. In this case, it is S3 ListObjects. There is a trivial tuple type corresponding to the outermost XML tag in the response from the S3 service, called XMLRootTagPlaceholder in this case. Beneath that tuple, there is the actual substance of the response from ListObjects, and in this case the example retrieves the Contents and the NextContinuationToken from the response. The contents is one "page" of object names, and the next continuation token is used to continue to the next page of results.